Data Analysis and Machine Learning Using R
Data Analysis and Machine Learning Using R
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>
Know More >>







Know More >>
Know More >>
Know More >>
Twitter
Word
Cloud
Twitter
Word
Cloud
Twitter
Word
Cloud
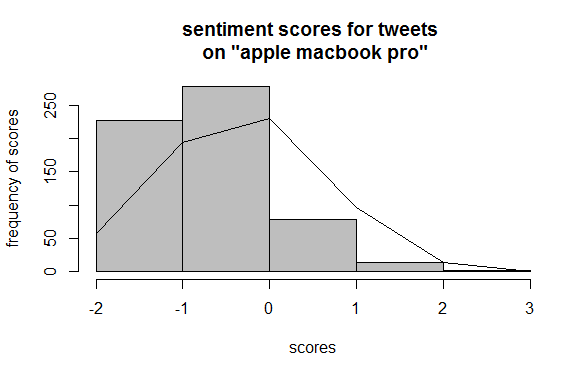
Sentiment
Analysis
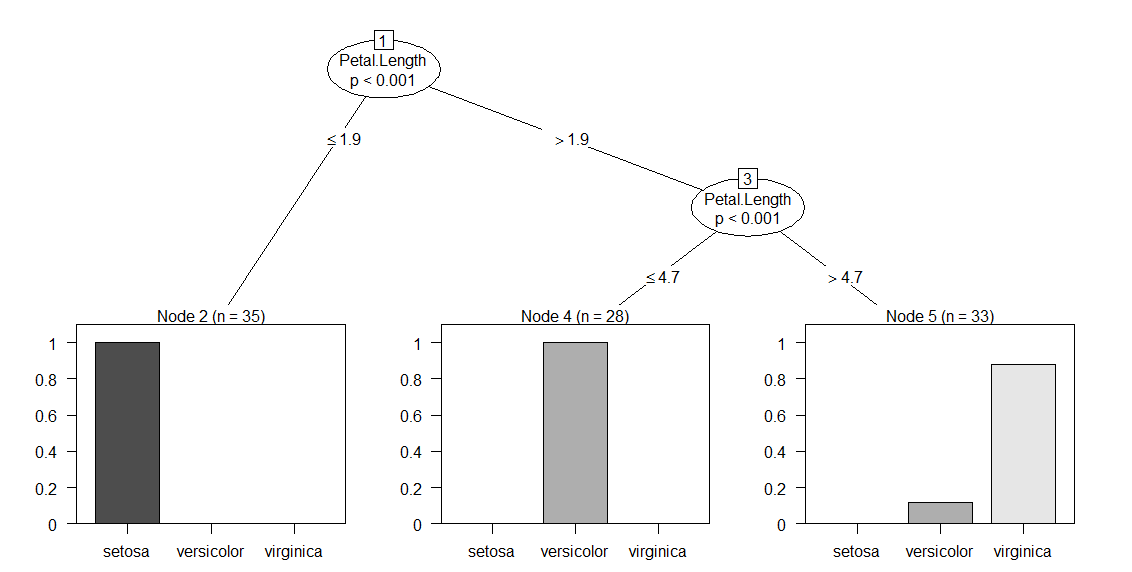
Tree
Know More >>
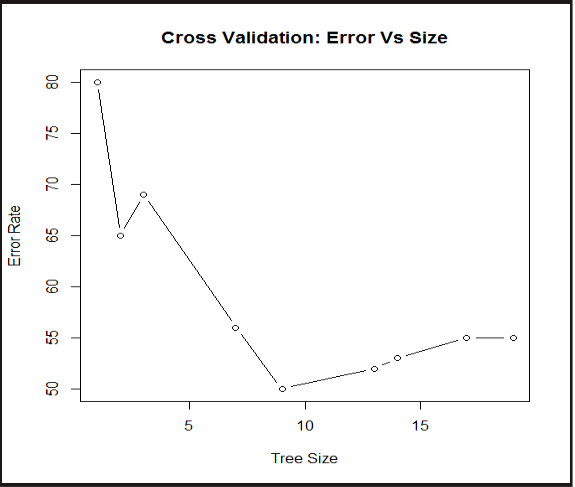
Validation
Tree
Know More >>
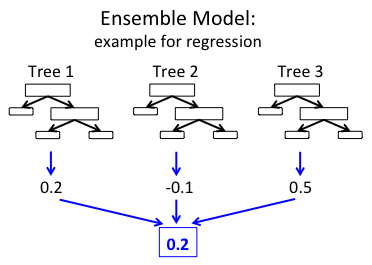
Forest
Know More >>
Know More >>
Know More >>
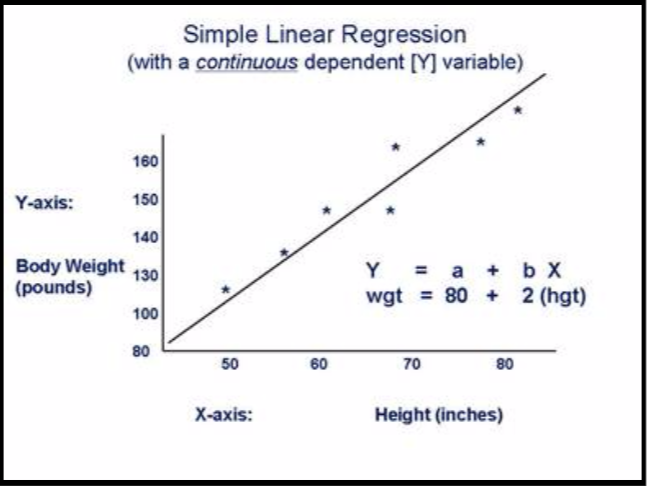
Regression
Know More >>
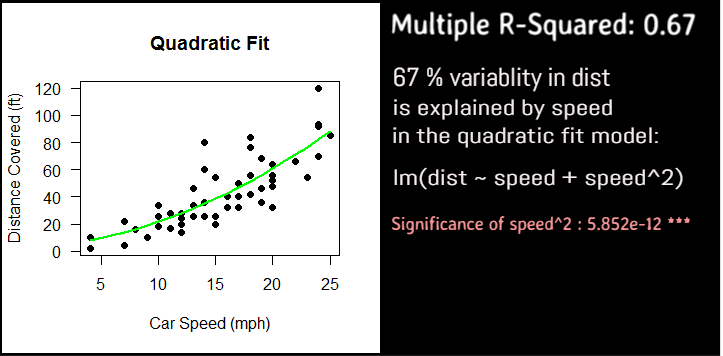
Regression
Know More >>
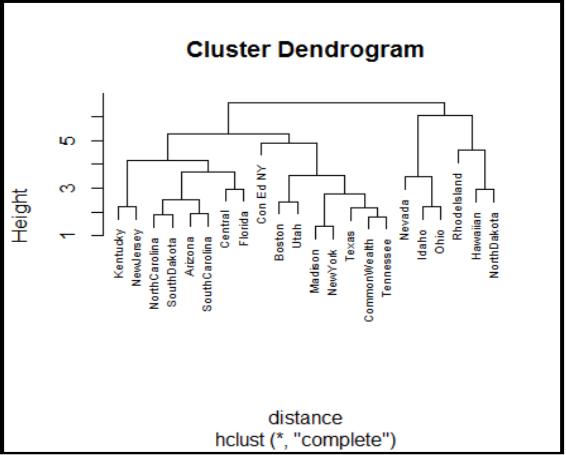
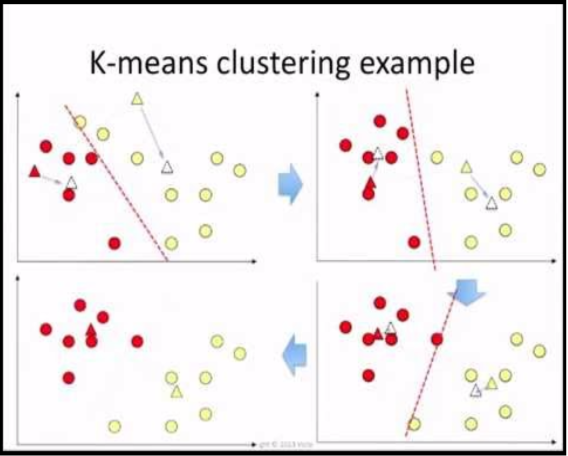
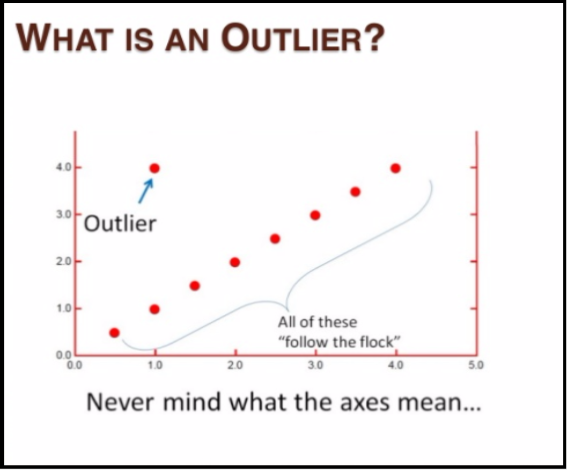
Clustering
Know More >>
Clustering
Know More >>
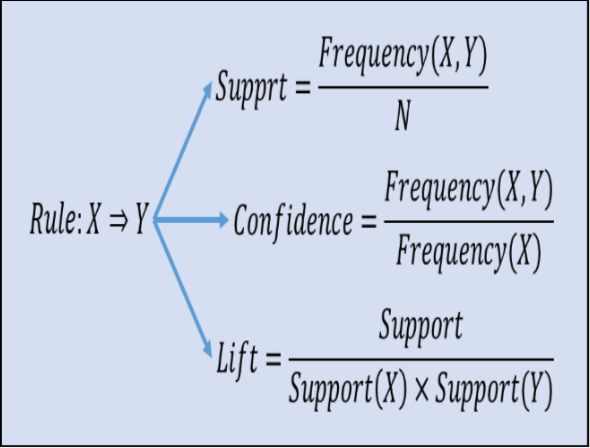
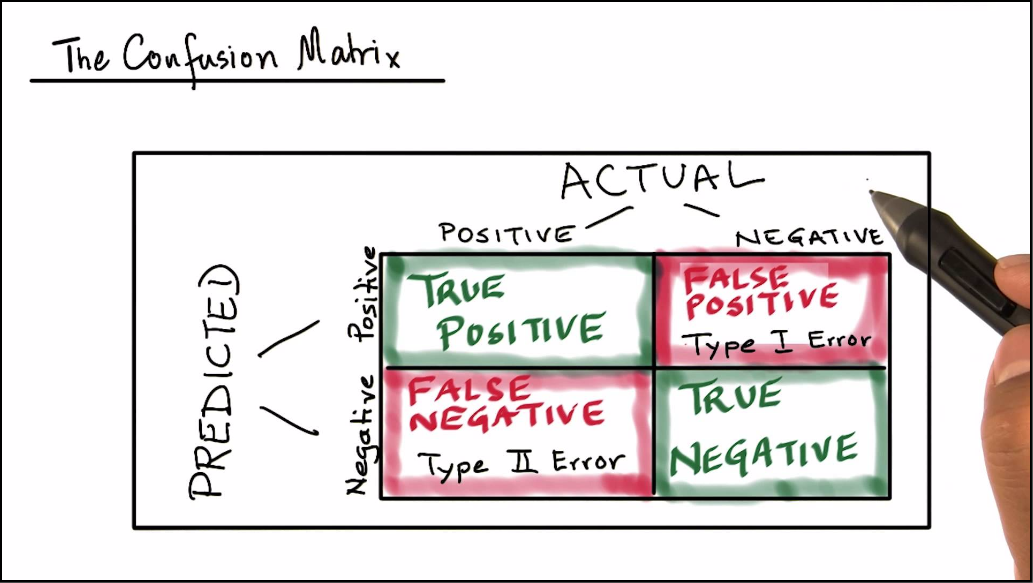
Vs
Precision

DATA ANALYSIS
Analysis of data is a process of inspecting, cleansing, transforming and modeling data with the goal of discovering a useful information, suggesting conclusions and supporting decision-making.
Exploratory Data Analysis
Once the data is cleaned, it can be analyzed. Analysts may apply a variety of techniques referred to as exploratory data analysis to begin understanding the messages contained in the data. The process of exploration may result in additional data cleaning or additional requests for data, so these activities may be iterative in nature. Descriptive statistics such as the average or median may be generated to help understand the data. Data visualization may also be used to examine the data in graphical format, to obtain additional insight regarding the messages within the data.
Exploratory data analysis - Wikipedia

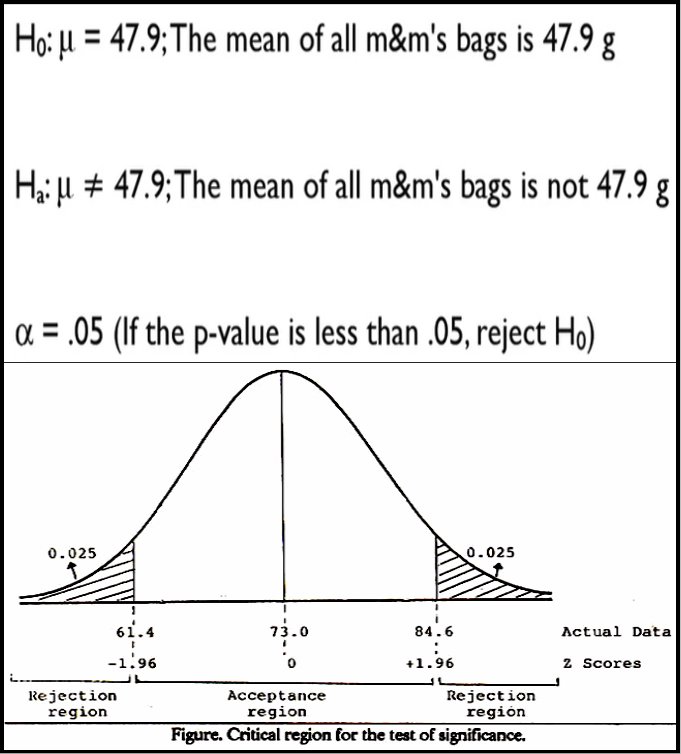
BIG DATA
Big data is a term for data sets that are so large or complex that the traditional data processing applications are inadequate to deal with them. Challenges include analysis, capture, data curation, search, sharing, storage, transfer, visualization, querying, updating and information privacy.
.
Example
An example of big data might be petabytes (1024 terabytes) or exabytes (1024 petabytes) of data consisting of billions to trillions of records of millions of people - all from different sources e.g. Web, sales, customer contact center, social media mobile data and so on.
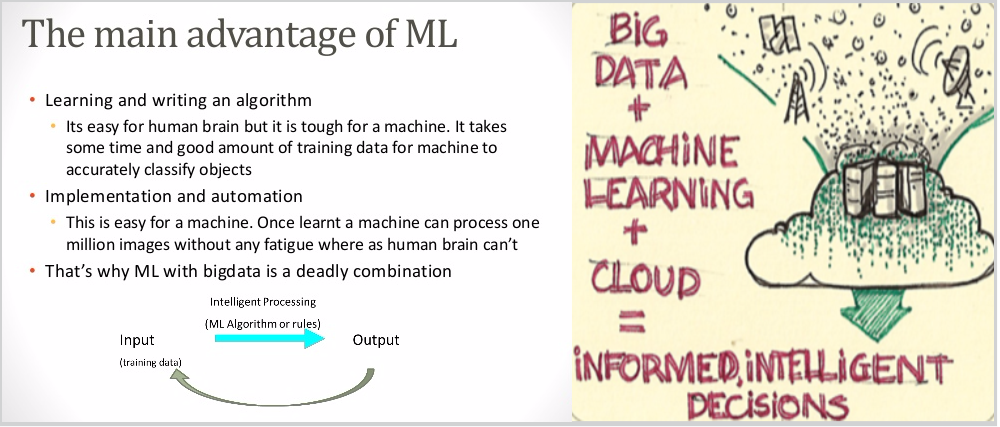
MACHINE LEARNING (ML)
It is the use of algorithms based on mathematical formulas or model, for finding and exploiting patterns in data. For example best-fit linear regression is a ML algorithm.
Suppose, in order to accomodate more functionality in your programming logic you have to keep writing if-then-else conditions and continuously tweak data for even small changes in logic then such a programming problem is a ML problem. Instead of humans trying to discover the patterns in the complex data set it can be given to machine to let it figure out how to solve it.
ML helps replacing 'human writing code' with 'human supplying data', that is, the system figures out what the person wants based on existing structure or patterns in data.
.
Examples
Auto-correct | Google page ranking | Netflix suggestions | Credit card fraud detection | Stock trading systems | Climate modeling and weather forecasting | Facial recognition | Self-driving cars | Simple data analysis
What Is Big Data Analysis Problem?
And
How Machine Learning Helps Solve It?
To analyse big and complex data such that it gives timely insights to enable decision making requires high speed data processing. However, there is a real difference between the resources to store big data and the resources available to analyse the data. Storing big data is not expensive these days but analysing big data requires high performance computer clusters, etc., which can be very expensive.
Tradition Statistical analysis focuses more on drawing inferences from sample results for the population and the statistical models may not be able to handle the big data complexity for predictive analysis. Machine learning is great for big data as it allows you to automate predictions using algorithms that analyse part of the data and extrapolate.